
分布式日志系统作为分布式存储系统的应用和拓展,其发展依托于分布式存储系统的发展,所以我们可以从分布式存储系统的发展,来看到分布式日志在技术圈走了多远,多少技术积淀。
在国外的发展现状64831
在分布式领域内,Google是一直走在最前沿的公司,没有之一。很多分布式技术的研究成果都来自Google。所以我们基本上可以从Google几篇重要论文,看出这一技术的发展。
2003年10月Google发布了第一篇关于分布式文件系统的论文,《The Google File System》,论文中详细的介绍了Google分布式文件系统GFS的设计原理。GFS是一个面向大规模数据密集型应用的,可伸缩的分布式文件系统。运行在廉价的普通硬件上面,提供灾难冗余的能力。与之类似的系统包括Sun公司的NFS和ZFS等。
随着服务类型的多样性,GFS无法满足对于信息量和响应速度要求差异特别大的应用后,2006年Google发布了《Bigtable: A Distributed Storage System for Structured Data》,论文中介绍了Google继GFS后,分布式存储的新系统Bigtable,Bigtable是一个结构化数据存储系统,他被设计用来处理海量数据,通常是分布在数千台普通服务器上的PB级别的数据。Google的很多项目使用Bigtable存储数据,包括Web索引,Google地图等等,这些应用对于数据的需求,无论是在信息量上,还是响应速度上,都差别很大。Bigtable成功的提供了一个灵活,高性能的解决方案。
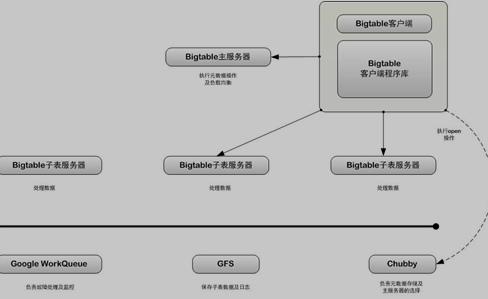
图 1 BigTable系统架构图
从Hadoop兴起以后,Google又发布三篇论文,主要阐述了基础设施如何支持庞大网络操作。其中一份中介绍了Caffeine,其为Google搜索引擎提供索引服务。在使用Caffeine之前,Google主要是采用MapReduce和GFS来构建搜索索引,在2010年,Google将搜索迁移到了Caffeine上面,Caffeine抛弃了MapReduce和GFS,将索引放置在了Bigtable上。
另外一篇介绍了Pregel,Pregel主要绘制大量网上信息之间关系的『图形数据库』。最吸引人的一篇是介绍Dremel的,是一种分析信息的方式,可跨越数千台服务器运行,允许『查询』大量的数据,如web文档集合,甚至是数以百万级的垃圾信息,根据Google提交的报告中显示,使用Dremel,你可以在几秒时间内处理PB级别的数据查询。
另外一个在分布式日志系统技术方面走的比较远的就是Facebook,Facebook的分布式日志框架Scribe。
Scribe是用来收集日志的服务器.它具备很强的扩展能力,并且网络故障及服务器节点故障,都不会对日志收集造成影响.大规模集群系统中每个节点上都运行了一个Scribe服务,这个Scribe服务器可以收集信息然后将信息发送到一个中央Scribe服务器(也可以是多个中央Scribe服务器)如果中央Scribe服务器(或中央服务器组)出现故障不可用的话,各个节点的Scribe服务器就会将日志信息写到本地磁盘待中央Scribe服务器恢复正常时再发送.中央Scribe服务器会将这些信息写文件保存到最终的磁盘地址,一般是NFS或者分布式文件系统中,有时也会把这些日志文件传输到其他层的Scribe服务器组中。
Scribe系统架构图
Scribe的独特之处是客户端日志实例包含两个字符串:类别和信息(a category and a message).类别(category)是对预期目标信息的高层次描述,可以在Scribe服务器中进行配置,这样就允许我们可以通过更改配置文件的方式转移数据而不需要更改代码。Scribe服务器也允许基于类别前缀(category prefix)进行配置,缺省状态下可以在文件路径中插入类别名称.灵活性和可扩展性,可通过“存储(store)“抽象。Stores可以通过一个配置文件静态配置,也可以在运行时无需停止服务器进行更改。论文网 分布式日志系统的发展研究现状:http://www.751com.cn/yanjiu/lunwen_72188.html