
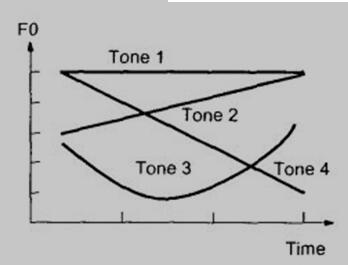
图1 汉语四个声调的基频变化
汉语声调直接与基音频率对应。因此通过描述基因频率随时间变化的轨迹,就可以得到定量地获取汉语声调[2-3]。汉语普通话的声调只有一声(阴平)、二声(阳平)、三声(上声)、四声(去声)和轻声,声调的变化就是浊音基音周期(或基音频率)的变化,各个韵母段中基音周期随时间的变化产生了声调,变化的轨迹称为声调曲线(见图1)。声调曲线从一个韵母的起始端开始,到韵母的终止端结束。不同声调的声调曲线开始段多是呈弯头段,皆呈上升趋向;末尾大多呈下降趋向,成为降尾段;而中间一段则各具特点,称为调型段。一般来说,弯头段和降尾段对声调的听辨不起作用,起作用的是调型段。而一段语音,它的起始和结尾处的波形幅度较小,要准确地测出这些地方的基音周期并不容易。因此,可将这两处的波形忽略,只测调型段这一部分波形的基音周期。由图1可以知道,一声的基频值相对较高,三声的基频值相对较低,且是四种声调中唯一非单调变化的;二声呈上升的趋势,四声呈下降的趋势。
自19世纪70年代开始,已经提出了若干有效的基频检测的算法,包括短时平均幅度差函数(AMDF)、自相关法(ACF)、倒谱法(Cepstrum)、小波变换法隐马尔可夫列(HMM)[7-11]。但是,由于汉语第三声的基音频率并非单调变化,而且基频值相对比较低,以上方法往往不能对汉语第三声的进行有效的检测。
另一方面,实际生活中更多的是两个人甚至多个人同时在说话,那么此时得到的语音信号就是一个多人的混合信号。处理这类混合信号是更加有实际应用价值的。目前人们对于多基频检测的研究主要集中在对音乐信号的研究,这是由于音乐信号具有稳定的基音频率,多音乐信号的基频检测就相对比较简单些。音乐信号的多基频检测对音乐的转录与分类有着很重要的作用[25-26],主要的方法有非线性最小二乘(Nonlinear Least-Squares),多重信号分类(Multiple Signal Classification),卡彭原理(Capon Principles),最大期望(Expectation Maximization)等。
但是对于语音信号,其基频具有很大的不稳定性,特别是汉语这种具有声调的语音信号,进行多基频检测就会更加的困难。1998年Meddis采用低级听觉模型将信号分解成多个频带,利用各频带的自相关函数(autocorrelation function,ACF)分离提取混叠语音基频,该方法假设频带只被混叠信号的其中一个信号支配。但同时含有两信号分量的频带大量存在,此时,用Meddis的方法分离提起基频就有可能存在提取的基频精度低的问题[1];1999年赵鹤鸣等提出基于小波变换的重叠语音基频提取及声调识别,其根据人耳对混叠语音信号精确的分辨能力,认为人耳滤波器本质上是一个小波变换[13],因此可以运用小波变换来分析重叠语音并进行特征提取;2000年赵鹤鸣等人提出了基于SHS(分谐波累加)的重叠语音基音分离检测方法,根据语音信号的短时平稳性,对基音周期进行动态跟踪,从而达到对重叠语音基音进行分离检测的效果;Alain de Cheveigne在2002年提出了YIN和MMM的基频检测方法;2004年日本东京大学信息科学与技术研究院提出了受迫高斯混合模型(Constrained Gaussian Mixture Model);2008年Anssi Klapuri提出利用听觉模型来进行多基频检测。但这些已经提出的算法都有着各种问题:频率分辨率不高或模型假设的合理性还不能得到证明等等,所以对于语音多基频检测仍然是不太成熟。本文就从着重对汉语语音的双基频检测的问题进行系统的研究。 MPDM复杂环境下汉语普通话双基频检测(2):http://www.751com.cn/tongxin/lunwen_75388.html